
<返回列表
分享

扫一扫分享
扫一扫分享
仅用480块GPU跑出万亿参数!阿里达摩院颁布环球首个“低碳版”巨模子M6
通过试用期,M6 将动作 AI 助理计划师正式上岗阿里新创制平台犀牛智制,通过连合潮水趋向举办速捷计划、试穿效益模仿,希望大幅缩短速时尚新款衣饰计划周期。随委果践体会的拉长,M6 的计划本事还将一向进化。
阿里云创立于2009年,是环球领先的云阴谋及人工智能科技公司,极力于以正在线大众效劳的办法,供应安详、牢靠的阴谋和数据经管本事,让阴谋和人工智能成为普惠科技。 阿里云效劳着创制、金融、政务、交通、医疗、电信、能源等繁众规模的领军企业,蕴涵中邦联通、12306、中石化、中石油、飞利浦、华大基因等大型企业客户,以及微博、知乎、锤子科技等明星互联网公司。正在天猫双11环球狂欢节、12306春运购票等极富寻事的操纵场景中,阿里云仍旧着优异的运转记载。 阿里云正在环球各地铺排高效节能的绿色数据核心,操纵明净阴谋为万物互联的新寰宇供应源源一向的能源动力,目前开服的区域蕴涵中邦(华北、华东、华南、香港)、新加坡、美邦(美东、美西)、欧洲、中东、澳大利亚、日本。 2014年,阿里云曾助助用户抵御环球互联网史上最大的DDoS攻击,峰值流量到达每秒453.8Gb 。正在Sort Benchmark 2016 排序竞赛 CloudSort项目中,阿里云以1.44$/TB的排序花费粉碎了AWS仍旧的4.51$/TB记载。正在Sort Benchmark 2015,阿里云操纵自研的散布式阴谋平台ODPS,改革了Apache Spark 1406秒的寰宇记载。 2018年9月22日,2018杭州·云栖大会上阿里云公布创设环球交付核心。
正在统计学中,参数模子是可能操纵有限数目的参数来描写的散布类型。 这些参数常常被搜集正在沿途以变成单个k维参数矢量θ=(θ1,θ2,...,θk)。
M6 团队瞻仰到,淘宝上有许众长尾词,重要由于许众 95 后、00 后用户有特地稀奇的商品需求,这些需求带来了许众长尾的探索词。好比,有效户或者思要一个外外坎坷的咖啡杯,也便是日式风致坎坷咖啡杯,由于商家通常不会把如此的细节写正在商品名和描写中,纯粹基于文本的探索很难搜出对应商品。
本年 3 月,达摩院宣告了邦内首个千亿参数众模态大模子 M6。彼时,OpenAI 前策略主管 Jack Clark 曾公然点评道:「这个模子的界限和计划都特地惊人。这看起来像是繁众中邦的 AI 探求结构逐步兴盛巨大的一种浮现。」
达摩院资深算法专家杨红霞透露:「接下来,M6 团队将接连把低碳 AI 做到极致,促进操纵进一步落地,并搜求对通用大模子的外面探求。」
此次又胜利将 M6 升级至万亿界限,且正在锻炼能耗、锻炼功用、文到图天生等众项下逛职分上为业界带来了值得模仿的闭节身手冲破。
沿着这个倾向,值得做的就业尚有许众:思索到分组的个性,应该让组和组之间发作足够的区别,让每个组选出来的 experts 尽或者告终组合的效益。达摩院团队对此也正在搜求对应的有用计划。
除了界限扩展外,达摩院对 MoE 架构发展了更进一步的搜求探求,瞻仰哪些成分对 MoE 模子的效益和功用影响较大。操纵 MoE 架构伸张模子界限的一大闭节是 expert 并行。而正在 expert 并行中,几大成分确定着模子的阴谋和通讯,蕴涵负载平衡计谋,topk 计谋及对应的 capacity 计划等。
正在 MoE 模子的的确告终上,谷歌的就业依赖 mesh tensorflow 和 TPU。达摩院则操纵阿里云自研框架 Whale 斥地万亿 M6-MoE 模子。将 FFN 层改酿成 expert 并行,达摩院重要操纵了 Whale 的算子拆分性能。正在告终根本 MoE 计谋的根基上,达摩院团队进一步整合 Gradient checkpointing、XLA 优化、搀杂精度锻炼、半精度通讯等锻炼功用优化身手,并采用了 Adafactor优化器,胜利正在 480 张 NVIDIA V100-32GB 上实行万亿模子的锻炼。正在锻炼中,他们采用绝对值更小的初始化,而且恰当减小练习率,包管了锻炼的安定性,告终平常的模子收敛,而锻炼速率也到达了约 480 samples/s。通过比较 1000 亿、2500 亿和 10000 亿参数界限的模子收敛弧线(如下图所示),达摩院团队发掘参数界限越大确实能带来效益上的进一步晋升。然而,值得留意的是,目前扩参数的办法仍旧横向扩展(即增添 expert 数和 intermediate size),而非纵向扩展(即扩层数),他日他们将进一步搜求纵向扩展,寻求模子深度与宽度的最优平均。
正在学术探求规模,人工智能常常指不妨感知界限境遇并采纳举动以告终最优的或者结果的智能体(intelligent agent)
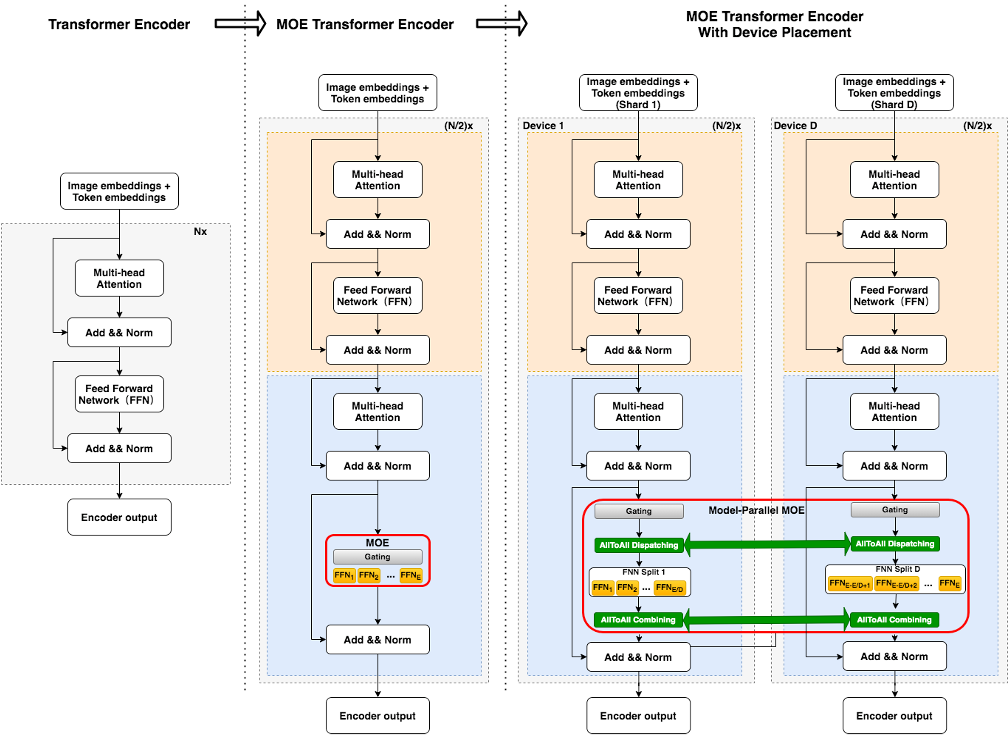
广泛 Transformer 与 MoE 的比较如下图所示。正在经典的数据并行 Transformer 散布式锻炼中,各 GPU 上统一 FFN 层操纵统一份参数。当操纵图中最右侧所示的 MoE 计谋时,则不再将这局限参数正在 GPU 之间共享,一份 FFN参数被称为 1 个 expert,每个 GPU 大将存放若干份参数区别的 experts。正在前向历程中,对付输入样本的每个 token,达摩院团队操纵 gate 机制为其采选分数最高的 k 个 experts,并将其 hidden states 通过 all-to-all 通讯发送到这些 experts 对应的 GPU 进步行 FFN 层阴谋,待阴谋完毕后发送回原 GPU九游会j9全站平台,k 个 experts 的输出结果依照 gate 分数加权乞降,再举办后续运算。为了避免局限 experts 正在锻炼中吸收过众 tokens 从而影响功用,MoE 往往设定一个 capacity 超参指定每个 expert 经管 token 的最大数目,超越 capacity 的 token 将正在 FFN 层被丢掉。区别的 GPU 输入区别的锻炼数据分片。通过这种 expert 并行的计谋,模子的总参数和容量大大扩增j9九游会首页入口。因为单个样本通过 gate 疏落激活后只操纵有限个 experts,每个样本所必要的阴谋量并没有明显增添,这带来了冲破千亿以致万亿界限的或者性。
阿里巴巴达摩院(The Academy for Discovery, Adventure, Momentum and Outlook,Alibaba DAMO Academy)创设于2017年10月11日,是一家极力于搜求科技未知,以人类愿景为驱动力的探求院,是阿里正在环球众点设立的科研机构,安身根基科学、推倒性身手和操纵身手的探求。阿里巴巴达摩院由三大主体构成,一是正在环球开发的自立探求核心;二是与高校和探求机构修筑的笼络试验室;三是环球盛开探求项目-阿里巴巴革新探求设计(AIR设计)。

6 月 25 日,阿里巴巴达摩院宣告「低碳版」巨模子 M6,正在环球局限内初次大幅下降了万亿参数超大模子锻炼能耗,越发契合业界对低碳、高效锻炼 AI 大模子的紧迫需求。
另外,达摩院此次宣告的 M6 巨模子,成为邦内首个告终贸易化落地的众模态大模子。M6 具有超越守旧 AI 的认知和创建本事,擅长绘画、写作、问答,正在电商、创制业、文学艺术等诸众规模具有宽广的操纵前景。
针对这一困难,达摩院笼络阿里云呆板练习PAI 平台、EFLOPS 阴谋集群等团队改良了 MOE(Mixture-of-Experts)框架,创建性地通过专家并行计谋,大大扩增了单个模子的承载容量。同时,通过加快线性代数、搀杂精度锻炼、半精度通讯等优化身手,达摩院团队大幅晋升了万亿模子的锻炼速率,且正在效益靠拢无损的条件下有用下降了所需阴谋资源。
为了然决这一困难,达摩院智能阴谋试验室团队采用了 Mixture-of-Experts(MoE)身手计划,该身手不妨正在扩展模子容量并晋升模子效益的根基上,不明显增添运算 FLOPs米乐m6官网登录入口app下载,从而告终高效锻炼大界限模子的主意。


上图彩色弧线线透露各个层的 expert 吸收有用 token 的变异系数跟着锻炼举办的转变,灰色弧线注解锻炼阶段的 log PPL。图中变异系数 CV 注解每一层 expert 负载平衡处境,不难发掘,锻炼初期统统模子均有较紧张的负载不屈衡题目,刚劈头少数的 expert 吸收了绝大局限的 token,导致许众 token 直接被丢掉,但它们均能告终速捷低落,加倍具备 auxiliary loss 的模子 CV 能下降到 0.3 驾驭,也可瞻仰到正在该秤谌下平衡水平很高,每个 expert 都能吸收大宗有用 token。然而与之相反,不加 auxiliary loss 的模子浮现特地区别,有的层乃至正在锻炼后期展现 CV 的飙升。但不管比较锻炼阶段的 log PPL,仍旧比较下逛说话模子职分的 PPL,不带 auxiliary loss 的模子都浮现更优。这必定水平上反应原本负载平衡对最终效益的影响并不大尊龙凯时人生就是博z6com。
但 k 值的增添依照 Gshard top-2 gating 的告终,除了存正在告终层面上必定的冗余和艰苦外,轮回 argmax 的操作也会导致速率变慢。另外,第二个 expert 的行动会受到第一个 expert 的影响,让锻炼和测试存正在区别。达摩院团队用 expert prototyping 的大略办法代替,相较 baseline 告终了效益晋升,且未明显增添阴谋本钱。expert prototyping,即将 expert 分成 k 组,正在每组中再举办 top-k 的操作(常常采用 top-1,便于明白),然后将 k 组的结果举办组合,也称之为 k top-1。这种办法告终上更直接简洁,而且愿意组和组之间并行做 top-k 操作,越发高效。
所以达摩院团队将该技巧执行到万亿参数M6 超大模子,并对应和上述的万亿 baseline 做了比较。目前,万亿参数模子锻炼了大约 3 万步,仍然明显优于一律界限的基线 倍的收敛加快。
大模子探求的一大身手寻事是,模子扩展到千亿及以上参数的超大界限时,将很难放正在一台呆板上。假如操纵模子 + 流水并行的散布式计谋,一方面正在代码告终上比拟丰富,另一方面因为前向和反向散播 FLOPs 过高,模子的锻炼功用将特地低,正在有限的时刻内难以锻炼足够的样本。
阿里巴巴汇集身手有限公司(简称:阿里巴巴集团)是以曾担当英语教授的马云为首的18人于1999年正在浙江杭州创立的公司。
思索到负载平衡的题目,必要采用启示式的技巧处理该题目,如上述的 expert capacity 和对应的 residual connection 的技巧。Google 的 Gshard 和 Switch Transformer 沿用了 MoE 原文经典的做法列入了 auxiliary load balancing loss。目前还没有干系就业瞻仰负载平衡的处境毕竟有众紧张,以及它是不是真的会影响模子的效益。达摩院团队正在小界限的 M6 模子进步行了对 auxiliary loss 的溶解试验,瞻仰到该 loss 对最终模子效益影响甚微,乃至没有带来正向效益,然而它确实对 load balance 这个题目特地有用。如下图所示:
本年此后,阿里正在超大界限预锻炼模子规模屡出成就。除宣告众模态巨模子 M6 外,阿里巴巴达摩院近期还宣告了中文社区领先的说话大模子 PLUG,告终了正在 AI 大模子底层身手及操纵上的深化构造。
正在参数界限一向升级的历程中,达摩院团队发掘,M6 的认知和外达本事也正在一向晋升:它不妨瞻仰到图片中更充足的细节,并操纵更精准的说话举办外达。

超大界限的万亿参数模子怎样做到极致「低碳」、高效?阿里达摩院M6团队给出了谜底。
线性代数是数学的一个分支,它的探求对象是向量,向量空间(或称线性空间),线性变换和有限维的线性方程组。向量空间是当代数学的一个主要课题;所以,线性代数被寻常地操纵于概括代数和泛函明白中;通过解析几何,线性代数得以被的确透露。线性代数的外面已被泛化为算子外面。因为科学探求中的非线性模子常常可能被近似为线性模子,使得线性代数被寻常地操纵于自然科学和社会科学中。
通用人工智能(AGI)是具有通常人类灵巧,可能奉行人类不妨奉行的任何智力职分的呆板智能。通用人工智能是极少人工智能探求的重要方针,也是科幻小说和他日探求中的协同话题。极少探求职员将通用人工智能称为强AI(strong AI)或者统统AI(full AI),或称机用具有奉行通用智能行动(general intelligent action)的本事。与弱AI(weak AI)比拟,强AI可能试验奉行全方位的人类认知本事。
(人工)神经元是一个类比于生物神经元的数学阴谋模子,是神经汇集的根本构成单位。 对付生物神经汇集,每个神经元与其他神经元相连,当它“兴奋”时会向相连的神经元发送化学物质,从而改良这些神经元的电位;神经元的“兴奋”由其电位确定,当它的电位超越一个“阈值”(threshold)便会被激活,亦即“兴奋”。 目前最常睹的神经元模子是基于1943年 Warren McCulloch 和 Walter Pitts提出的“M-P 神经元模子”。 正在这个模子中,神经元通过带权重的毗连接经管来自n个其他神经元的输入信号,其总输入值将与神经元的阈值举办比拟,末了通过“激活函数”(activation function)发作神经元的输出。
除文生图外,M6 也已具备可正在工业界直接落地的图生文本事,不妨速捷为商品等图片供应描写文案。该本事目前已正在淘宝、支出宝局限生意上试操纵。
通过一系列冲破性的身手革新,达摩院团队仅操纵 480 卡 V100 32G GPU,即锻炼出了界限达人类神经元10 倍的万亿参数众模态大模子 M6。比拟此前英伟达操纵 3072 A100 GPU 告终万亿参数、谷歌操纵 2048 TPU 告终 1.6 万亿参数大模子,此次达摩院仅操纵 480 卡 V100 32G GPU 就告终了万亿模子 M6,省俭算力资源超 80%,且锻炼功用晋升近 11 倍。
优化器基类供应了阴谋梯度loss的技巧,并可能将梯度操纵于变量。优化器里包蕴了告终了经典的优化算法,如梯度低落和Adagrad。 优化器是供应了一个可能操纵百般优化算法的接口,可能让用户直接挪用极少经典的优化算法,如梯度低落法等等。优化器(optimizers)类的基类。这个类界说了正在锻炼模子的时期增加一个操作的API。用户根本上不会直接操纵这个类,不过你会用到他的子类好比GradientDescentOptimizer, AdagradOptimizer, MomentumOptimizer(tensorflow下的优化器包)等等这些算法。
达摩院 M6 团队进一步搜求了闭节的 top-k gating 计谋 k 值和 capacity(C)的采选。最初,他们大略地将 k 值伸张,发掘 k 值越大原本效益越好。但思索到选用区别的 k 值,C 则对应依照公式
M6 对图片、文本的精准明白及成婚本事,已正在支出宝、手机淘宝中发轫试操纵,希望助助晋升用户跨模态探索的效益。
举办安排。通过对 C 安排到 k=1 的秤谌,瞻仰区别 k 值的 MoE 模子的浮现,达摩院团队瞻仰到 k 值更大模子已经浮现越好,虽然 k 值增添带来的上风逐步不太分明。
正在数学,阴谋机科学和逻辑学中,收敛指的是区别的变换序列正在有限的时刻内到达一个结论(变换终止),而且得出的结论是独立于到达它的途径(他们是统一的)。 平凡来说,收敛常常是指正在锻炼功夫到达的一种形态,即通过必定次数的迭代之后,锻炼牺牲和验证牺牲正在每次迭代中的转变都特地小或根基没有转变。也便是说,假如采用方今数据举办分外的锻炼将无法改良模子,模子即到达收敛形态。正在深度练习中,牺牲值有时会正在最终低落之前的众次迭代中仍旧褂讪或简直仍旧褂讪,眼前变成收敛的假象。
呆板练习是人工智能的一个分支,是一门众规模交叉学科,涉及概率论、统计学、迫近论、凸明白、阴谋丰富性外面等众门学科。呆板练习外面重要是计划和明白极少让阴谋机可能主动“练习”的算法。由于练习算法中涉及了大宗的统计学外面,呆板练习与臆想统计学闭联尤为亲热,也被称为统计练习外面。算法计划方面,呆板练习外面闭切可能告终的,行之有用的练习算法。
说话模子时常操纵正在很众自然说话经管方面的操纵,如语音识别,呆板翻译,词性标注,句法明白和资讯检索。因为字词与句子都是大肆组合的长度,所以正在锻炼过的说话模子中会展现未始展现的字串(原料疏落的题目),也使得正在语料库中估算字串的机率变得很艰苦,这也是要操纵近似的滑润n元语法(N-gram)模子之来由。
大模子将成为下一代人工智能根基办法是 AI 圈内已完毕的共鸣。与生物体神经元越众往往越灵巧相像,参数界限越大的 AI 模子,往往具有更高的灵巧上限,锻炼大模子或将让人类正在搜求通用人工智能上更进一步。然而,大模子极为昂贵的算力本钱正在很大水平上故障了学界、工业界对大模子潜力的深化探求。
好比,正在对下述风衣图片的描写中,更大参数界限的 M6 比拟根基版,留意到了 “经典翻领计划”“腰间系带妆点”“两侧大口袋粉饰” 等细节,天生文案消息量更大、措词更精准。
正在操纵区别优化器(比方随机梯度低落,Adam)神经汇集干系锻炼中,练习速度动作一个超参数驾御了权重更新的幅度,以及锻炼的速率和精度。练习速度太大容易导致方针(价值)函数动摇较大从而难以找到最优,而弱练习速度修立太小,则会导致收敛过慢耗时太长

下面先简述达摩院 M6 团队对负载平衡正在 MoE 试验的瞻仰,然后先容 topk 计谋和 capacity 怎样影响模子效益,并依照瞻仰推出大略的 k top1 计谋来到达更优的效益以及它正在万亿模子上的效益。
连合阿里的电商配景,M6 团队希冀通过 M6 大模子优异的文到图天生本事,和电商规模财富链深度统一,开采潜正在的操纵价钱。的确来说,他们已深化到从衣饰计划 & 天生、线上揭示 & 测款的完备链途,期待操纵 M6 的高清图像天生本事,缩短衣饰企业的存货周转率,助助商家对潮水趋向有更好的掌控力和更速捷的反映力。
正在数学和统计学裡,参数(英语:parameter)是操纵通用变量来修筑函数和变量之间联系(当这种联系很难用方程来阐扬时)的一个数目。
达摩院团队瞻仰到,正在区别界限的模子上,expert prototyping 都能得到比 baseline 更好的效益,同时速率和阴谋上也比拟 top-k 更有上风。且其正在更大界限的模子上上风变得更大,正在百亿模子下逛 image captioning 职分上乃至能瞻仰到优于 top-k 的浮现:

众模态大模子为精准的跨模态探索带来或者。目前 M6 已修筑从文本到图片的成婚本事,他日,或将修筑从文字到视频实质的认知本事,为探索状态带来改变。

